Using GANs with Limited Data: How Synthetic Content Generation with AI Can Impact your Business

Using GANs with Limited Data: How Synthetic Content Generation with AI Can Impact your Business
Generative Adversarial Networks (GANs) have shown great promise by yielding some impressive results in generating new data from existing datasets. A Generative Adversarial Networks (GAN) is a machine learning technique that enables computer programs to create and modify data in many forms. They can be used to generate realistic-looking faces, for example, or to alter the audio of a recorded speech.
To get good results with most AI systems, there is a need for a vast dataset that the AI model can learn from. Even with GANs, generating new images or audio still requires a lot of data, and these are not always available.
What are Generative Adversarial Networks
GANs are computational structures that pit two neural networks against one other (thus the name “adversarial”) to produce fresh, synthetic examples of data that can pass for real data. A typical example of a GAN architecture consists of two neural networks: a generator and a discriminator. The generator generates new data instances while the discriminator assesses them for authenticity; that is, the discriminator determines whether each instance of data it examines corresponds to the actual training dataset or not. As training progresses, the generator becomes better at generating realistic samples, while the discriminator becomes better at distinguishing between real and synthetic data.
GANs are already being used for:
- Image enhancement
- Image augmentation
- 3D modelling generation (digital sculpture)
- Generating “visually appealing” images (e.g., adding the look of a real photograph)
- Generating data such as CT scans and MRIs (e.g., detecting whether a CT scan is abnormal or not)
- Generating fake but realistic images and videos (e.g., detecting if a video is fake or not)
- Identifying legal documents that may be fraudulent (e.g., identifying fake birth certificates)
- Identifying work that may be plagiarised (e.g., detecting whether a college paper is plagiarised or not)
GANs and AI will continue to benefit organisations in many ways, including reducing medical errors, improving customer service, providing better security, and reducing fraud.
GANs and the data challenge
Generative adversarial networks have been successfully used to learn from input data to another. However, the success of the existing GAN training methods hinges critically on the availability of a large dataset with diverse content.
GANs require a lot of data because they use neural networks to generate new images and audio. Neural networks — which mimic the mechanisms of the brain — are famously good at pattern recognition and classification but notoriously bad at creativity: they can’t create new things without a lot of training data. The more complex the item you want the neural network to create, the more training data it needs, which means that generating new images or audio with GANs requires an enormous amount of data.
When such a large dataset is unavailable, the discriminator often overfits and causes divergence in the training process. An NVIDIA team proposed an adaptive discriminator augmentation mechanism that significantly stabilises training with limited data to mitigate this problem. The results show that the method can significantly stabilise GAN training in limited data regimes and that it can also improve generalisation performance.
This mechanism aims to augment the available training images with random distortions so that the network never sees the same exact image twice. Instead, it sees one that’s either been flipped, rotated, or has the colours adjusted.
The costs of large datasets are prohibitive for many organisations, but the NVIDIA project seeks to reduce the amount of data required for most applications of GANs. With less training data needed, more organisations can benefit from using GANs because it will be easier for them to generate results without spending as much time and money on finding and gathering more data. It also means that they will be able to generate and test out more scenarios before making a business decision.
Impact of GANs on organisations
GANs are already being used in organisations to improve product design and target marketing, generate characters and sounds in video games, develop and test fashion items, and create writing assistants. But the ability to use fewer training data can make it easier to use and make it more accurate in some cases. Aside from enabling machines to generate realistic images, they can also be used to create entirely new types of images, like fonts.
Manufacturing
Engineers can produce a variety of design options using generative design software by selecting characteristics such as weight, size, materials, operating, and manufacturing circumstances. They can then choose the best design for a future product and have it manufactured. General Motors are already using this technology to improve the seat brackets where seat belts are fastened.
Healthcare
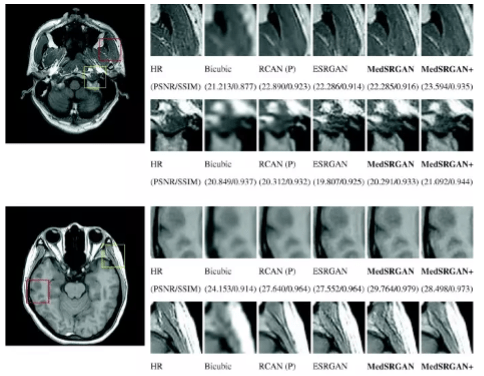
There is an urgent need to lessen the detrimental effects of radiation on patients when employing low dose scanning in Computer Tomography (CT) to reduce the harmful impact on persons with particular health conditions such as lung cancer. And at the same time, the limited scans obtained from such patients be of the highest quality and meet the specifications.
Although the ultra-resolution that GANs provide can improve the collected images’ quality and can effectively reduce noise, GAN implementation in the medical field is slow because of the numerous experiments and trials required due to safety concerns. When dealing with healthcare, it is necessary to enlist the help of a number of domain specialists to assess the models and ensure that the denoising does not distort the image’s true content in any manner that could lead to a misdiagnosis.
Marketing
Promoting a product or service frequently requires the creation of distinctive but repeatable content, such as photographing photo models. Rosebud AI has created a Generative Photos app that takes advantage of recent developments in GANs to meet this opportunity.
The program generates photos of fashion models that do not exist. This is accomplished by replacing the faces on stock photographs of real models with artificial ones. The most impactful part about this project is that you can replace the face with a created one and tweak it in multiple ways. The company used the adaptive discriminator augmentation mechanism developed by NVIDIA. Another important application of GANs in marketing is the creation of new logotypes. By feeding the network with several logos that the operator likes, a new fascinating logo can be created.

The original image is the leftmost; the other three are generated using the generative photos app.
Entertainment
FaceApp and the ZAO Face Mapping app are examples of applications that allow users to change a person’s facial look or even replace another person’s face in a video with their own. FaceApp employs a face-editing method based on StyleGAN. It can work with images and films, but the apps recommend adjustments to ensure that the created frames are temporally consistent.
Creating Synthetic Data
However, one of the most promising, yet controversial use cases, is data augmentation. This means creating artificially generated training data sets to improve machine learning models that need more data to work well. An Israeli startup, DataGen, works with this approach to create synthetic data that is then used by businesses and organisations. The company is concentrating its efforts on bridging the gap between real and simulated data so that the information gained from the latter can be applied in real-world circumstances.
Despite their great potential, GANs are not without flaws, and the most significant one is their instability. GANs are very complicated to train, and because the models may not have enough knowledge in the training data to grasp how certain things work in real life, they may produce images or data with artefacts. For example, given a collection of portrait photographs, the network may model human faces but struggle to understand what specific clothing components should look like. As a result, it is critical to carefully select data that is only relevant to the anticipated outcome.
Conclusion
The breakthrough by NVIDIA on using limited data to train GANs enables companies to reduce the number of training images or training data by a factor of up to twenty or more while still getting great results. This means GANs can tackle tougher problems, but the vast quantities of data needed before are either too expensive or simply not possible to obtain. This is where synthetic data can help organisations.
Artists can recreate the style of rare works where you don’t need tens of thousands of images by a particular artist or a particular medium to train on; medical experts could produce all kinds of diverse data to build computer models to train others to accelerate the diagnosis of rare pathologies. In general, developers and researchers around the world are going to find that this technology allows them to pursue breakthroughs by using synthetic data and GAN technology in all kinds of settings that they couldn’t apply it before
As such, GANs should be of great interest to businesses because they can speed up AI development and make AI systems far more efficient. But this technology will also enable deepfakes that are too sophisticated for any human to spot without AI assistance.
On a more positive note, we will also be able to acquire data more efficiently and at a cheaper cost than we can today, as the high-quality “fakes” cost a fraction of what it would cost to obtain the data previously. This will change the way we use technology and, in the long run, have a lasting impact on how technology helps our businesses.
Cover image: Storyblocks

Dr Mark van Rijmenam
Dr. Mark van Rijmenam, widely known as The Digital Speaker, isn’t just a #1-ranked global futurist; he’s an Architect of Tomorrow who fuses visionary ideas with real-world ROI. As a global keynote speaker, Global Speaking Fellow, recognized Global Guru Futurist, and 5-time author, he ignites Fortune 500 leaders and governments worldwide to harness emerging tech for tangible growth.
Recognized by Salesforce as one of 16 must-know AI influencers , Dr. Mark brings a balanced, optimistic-dystopian edge to his insights—pushing boundaries without losing sight of ethical innovation. From pioneering the use of a digital twin to spearheading his next-gen media platform Futurwise, he doesn’t just talk about AI and the future—he lives it, inspiring audiences to take bold action. You can reach his digital twin via WhatsApp at: +1 (830) 463-6967.


