Why We Should Be Careful When Developing AI

Why We Should Be Careful When Developing AI
Artificial intelligence offers a lot of advantages for organisations by creating better and more efficient organisations, improving customer services with conversational AI and reducing a wide variety of risks in different industries. Although we are only at the start of the AI revolution, we can already see that artificial intelligence will have a profound effect on our lives, both positively and negatively.
The financial impact of AI on the global economy is estimated to reach US$15.7 trillion by 2030, with 40% of jobs expected to be lost due to artificial intelligence, and global venture capital investment in AI is growing to greater than US$27 billion in 2018. Such estimates of AI potential relate to a broad understanding of its nature and applicability.
The Rapid Developments of AI
AI will eventually consist of entirely novel and unrecognisable forms of intelligence, and we can see the first signals of this in the rapid developments of AI.
In 2017, Google’s Deepmind developed AlphaGo Zero, an AI agent that learned the abstract strategy board game Go with a far more expansive range of moves than chess. Within three days, by playing thousands of games against itself, and without the requirement of large volumes of data (which would normally be required in developing AI), the AI agent beat the original AlphaGo, an algorithm that had beaten 18-time world champion Lee Sedol.
At the end of 2018, Deepmind went even further by creating AlphaStar. This AI system played against two grandmaster StarCraft II players and won. In a series of test matches, the AI agent won 5–0. Thanks to a deep neural network, trained directly from raw game data via both supervised and reinforcement learning, it was able to secure the victory. It quickly surpassed professional players with its ability to combine short-term and long-term goals, respond appropriately to situations (even upon receipt of imperfect information) and adapt to unexpected events.
In November 2018, China’s state news agency Xinhua developed AI anchors to present the news. The AI agents are capable of simulating the voice, facial movements, and gestures of real-life broadcasters
Early in 2019, OpenAI, (the now for-profit AI research organisation originally founded by Elon Musk) created GPT2. The AI system is so efficient in writing a text-based on just a few lines of input that OpenAI decided not to release the comprehensive research to the public, out of fear of misuse. Since then, there have been multiple successful replications by others.
A few months later, in April 2019, OpenAI trained five neural networks to beat a world champion e-sports team in the game Dota 2—a complex strategy game that requires players to collaborate to win. The five bots had learned the game by playing against itself at a rate of a staggering 180 years per day.
In September 2019, researchers at OpenAI trained two opposing AI agents to play the game hide and seek. After nearly 500 million games, the two artificial agents were capable of developing complex hiding and seeking strategies that involved tool use and collaboration.

Source: OpenAI
AI is also rapidly moving outside the research domain. Most of us have become so familiar with the recommendation engines of Netflix, Facebook or Amazon; AI personal assistants such as Siri, Alexa or Home; AI lawyers such as ROSS; AI doctors such as IBM Watson; AI autonomous cars developed by Tesla or AI facial recognition developed by numerous companies. AI is here and ready to change our society.
The Rapid AI Developments Should be a Cause for Concern
However, although AI is being developed as such a rapid pace, AI itself is still far from perfect. Too often, artificial intelligence is biased. Biased AI is a serious problem and challenging to solve as AI is trained using biased data and developed by biased humans. This has resulted in many examples of AI gone rogue, including facial recognition systems not recognising people with dark skin or Google translate that is gender-biased (the Turkish language is gender-neutral, but Google swaps the gender of pronouns when translating).
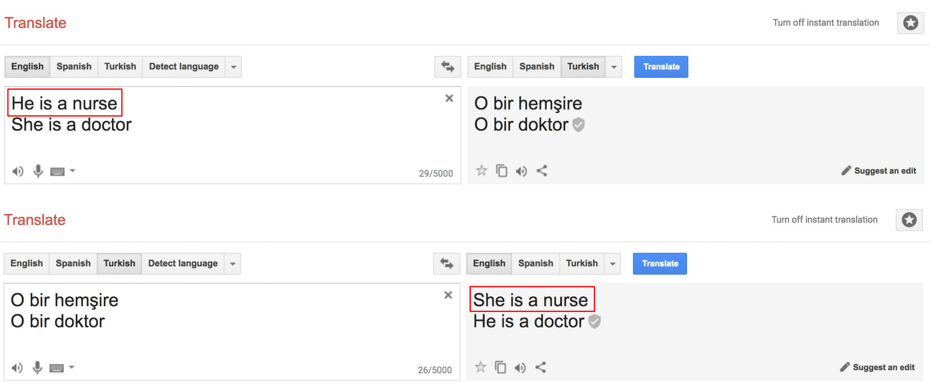
Source: Stateof.ai
We have also seen many examples where AI has been used to cause harm deliberately. These examples include deepfakes to generate fake news and hoaxes or privacy-invading facial recognition cameras. On the other hand, machine learning models can also easily be tricked by using an unnoticeable universal noise filter, where adding a sticker next to an image completely changes the output.
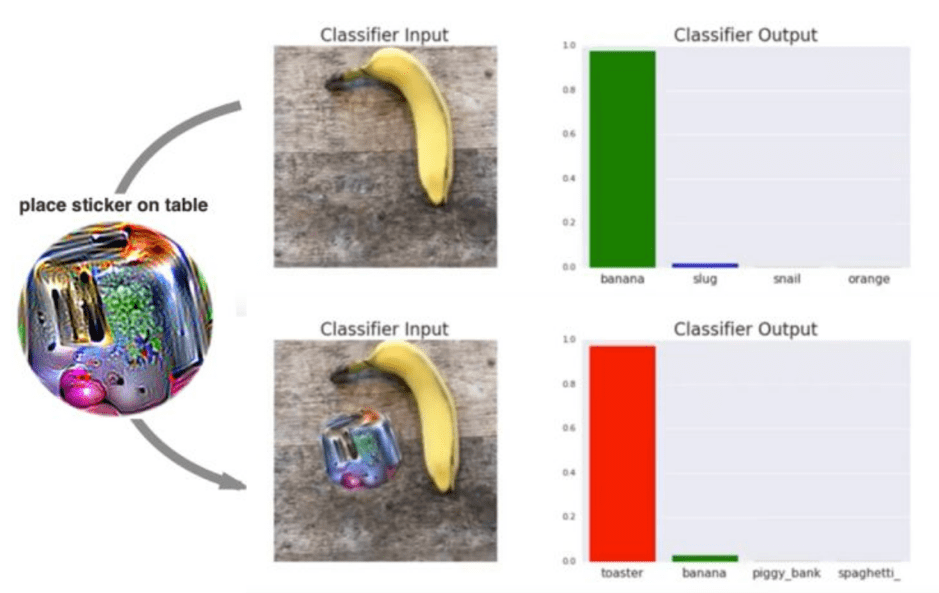
Source: stateof.ai
Case in point is that although researchers are rapidly developing very advanced AI, there are still a lot of problems with AI when we bring AI into the real world. The more advanced AI becomes, and the less we understand the inner workings of AI, the more problematic this becomes.
We Need to Develop Responsible Artificial Intelligence
Governments and organisations are all in an AI arms race to be the first to develop Artificial General Intelligence (AGI) or Super Artificial Intelligence (SAI). AGI refers to AI systems having autonomous self-control and self-understanding and the ability to learn new things to solve a wide variety of problems in different contexts. SAI is intelligence far exceeding that of any person, however clever. SAI would be able to manipulate and control humans as well as other artificial intelligent agents and achieve domination. The arrival of SAI will be the most significant event in human history, and if we get it wrong, we have a serious problem.
Therefore, we need to shift our focus from rapidly developing the most advanced AI to developing Responsible AI, where organisations exercise strict control, supervision and monitoring on the performance and actions of AI.
Failures in achieving Responsible AI can be divided into two, non-mutually exclusive categories: philosophical failure and technical failure. Developers can build the wrong thing so that even if AGI or SAI is achieved, it will not be beneficial to humanity. Or developers can attempt to do the right thing but fail because of a lack of technical expertise, which would prevent us from achieving AGI or SAI in the first place. The border between these two failures is thin, because ‘in theory, you ought first to say what you want, then figure out how to get it. In practice, it often takes a deep technical understanding to figure out what you want’ [1].
Not everyone believes in the existential risks of AI, simply because they say AGI or SAI will not cause any problems or because if existential risks do indeed exist, AI itself will solve these risks, which means that in both instances, nothing happens.
Nevertheless, SAI is likely to be extremely powerful and dangerous if not appropriately controlled. Simply because AGI and SAI will be able to reshape the world according to its preferences, this may not be human-friendly. Not because it would hate humans, but because it would not care about humans.
It is the same that you might go ‘out of your way’ to prevent on stepping on an ant when walking, but you would not care about a large ants nest if it happened to be at a location where you plan a new apartment building. In addition, SAI will be capable of resisting any human control. As such, AGI and SAI offer different risks than any other known existential risk humans faced before, such as nuclear war, and requires a fundamentally different approach.
Algorithms are Literal
To make matters worse, algorithms, and therefore AI, are extremely literal. They pursue their (ultimate) goal literally and do exactly what is told while ignoring any other, important, consideration. An algorithm only understands what it has been explicitly told. Algorithms are not yet, and perhaps never will be, smart enough to know what it does not know. As such, it might miss vital considerations that we humans might have thought off automatically.
So, it is important to tell an algorithm as much as possible when developing it. The more you tell, i.e. train, the algorithm, the more it considers. Next to that, when designing the algorithm, you must be crystal clear about what you want the algorithm to do and not to do. Algorithms focus on the data they have access to and often that data has a short-term focus. As a result, algorithms tend to focus on the short term. Humans, most of them anyway, understand the importance of a long-term approach. Algorithms do not unless they are told to focus on the long-term.
Developers (and managers) should ensure algorithms are consistent with any long-term objectives that have been set within the area of focus. This can be achieved by offering a wider variety of data sources (the context) to incorporate into its decisions and focusing on so-called soft goals as well (which relates to behaviours and attitudes in others). Using a variety of long-term- and short-term-focused data sources, as well as offering algorithms soft goals and hard goals, will help to create a stable algorithm.
Unbiased, Mixed Data Approach to Include the Wider Context
Apart from the right goals, the most critical aspect in developing the right AI is to use unbiased data to train an AI agent as well as minimise the influence of the biased developer. An approach where AI learns by playing against itself and is only given the rules of a game can help in that instance.
However, not all AI can be developed by playing against itself. Many AI systems still require data, and they require a lot of, unbiased, data. When training an AI agent, a mixed data approach can help to calibrate the different data sources for their relative importance, resulting in better predictions and better algorithms. The more data sources and the more diverse these are, the better the predictions of the algorithms will become.
This will enable AI learns from its environment and improve over time due to deep learning and machine learning. AI is not limited by information overload, complex and dynamic situations, lack of complete understanding of the environment (due to unknown unknowns), or overconfidence in its own knowledge or influence. It can take into account all available data, information and knowledge and is not influenced by emotions.
Although reinforcement learning, and increasingly transfer learning – applying knowledge learned in one domain in a different but related domain – would allow AI to rework its internal workings, AI is not yet sentient, cognisant or self-aware. That is, it cannot interpret meaning from data. AI might recognise a cat, but it does not know what a cat is. To the AI, a cat is a collection of pixel intensities, not a carnivorous mammal often kept as an indoor pet.
AI are Black Boxes
Another problem with AI is that they are black boxes. Often, we do not know why an algorithm comes to a certain decision. They can make great predictions, on a wide range of topics, but that does not mean AI decisions are error-free. On the contrary, as we have seen with Tay. AI ‘preserves the biases inherent in the dataset and its underlying code’, resulting in biased outputs that could inflict significant damage.
In addition, how much are these predictions worth, if we don’t understand the reasoning behind it? Automated decision-making is great until it has a negative outcome for you or your organisation, and you cannot change that decision or, at least, understand the rationale behind that decision.
Whatever happens inside an algorithm is sometimes only known to the organisation that uses it, yet quite often this goes beyond their understanding as well. Therefore, it is important to have explanatory capabilities within the algorithm, to understand why a certain decision was made.
The Need for Explainable AI
The term Explainable AI (XAI) was first coined in 2004 as a way to offer users of AI an easily understood chain of reasoning on the decisions made by the AI, in this case especially for simulation games [2]. XAI relates to explanatory capabilities within an algorithm to help understand why certain decisions were made. With machines getting more responsibilities, they should be held accountable for their actions. XAI should present the user with an easy to understand the chain of reasoning for its decision. When AI is capable of asking itself the right questions at the right moment to explain a certain action or situation, basically debugging its own code, it can create trust and improve the overall system.
Explainable AI should be an important aspect of any algorithm. When the algorithm can explain why certain decisions have been / will be made and what the strengths and weaknesses of that decision are, the algorithm becomes accountable for its actions. Just like humans are. It can then be altered and improved if it becomes (too) biased or if it becomes too literal, resulting in better AI for everyone.
Ethical AI and Why That is So Difficult
Responsible AI can be achieved by using unbiased data, minimising the influence of biased developers, having a mixed data approach to include the context and by developing AI that can explain itself. The final step in developing responsible Ai is by incorporating ethics into AI.
Ethical AI is completely different from XAI, and it is an enormous challenge to achieve. The difficulty with creating an AI capable of ethical behaviour is that ethics can be variable, contextual, complex and changeable [3, 4, 5]. The ethics we valued 300 years ago are not the same in today’s world. What we deem ethical today might be illegal tomorrow. As such, we do not want ethics in AI to be fixed, as it could limit its potential and affect society.
AI ethics is a difficult field because the future behaviour of advanced forms of a self-improving AI are difficult to understand if the AI changes its inner workings without providing insights on it; hence, the need for XAI. Therefore, ethics should be part of AI design today to ensure ethics is part of the code. We should bring ethics to the code. However, some argue that ethical choices can only be made by beings that have emotions since ethical choices are generally motivated by these.
Already in 1677, Benedictus de Spinoza, one of the great rationalists of 17th-century philosophy, defined moral agency as ‘emotionally motivated rational action to preserve one’s own physical and mental existence within a community of other rational actors’. However, how would that affect artificial agents and how would AI ethics change if one sees AI as moral things that are sentient and sapient? When we think about applying ethics in an artificial context, we have to be careful ‘not to mistake mid-level ethical principles for foundational normative truths’ [6].
Good versus Bad Decisions
In addition, the problem we face when developing AI ethics, or machine ethics, is that it relates to good and bad decisions. Yet, it is unclear what good or bad means. It means something different for everyone across time and space. What is defined good in the Western world might be considered bad in Asian culture and vice versa. Furthermore, machine ethics are likely to be superior to human ethics.
First, because humans tend to make estimations, while machines can generally calculate the outcome of a decision with more precision. Secondly, humans do not necessarily consider all options and may favour partiality, while machines can consider all options and be strictly impartial. Third, machines are unemotional, while with humans, emotions can limit decision-making capabilities (although at times, emotions can also be very useful in decision-making). Although it is likely that AI ethics will be superior to human ethics, it is still far away.
The technical challenges to instil ethics within algorithms are numerous because as their social impact increases, ethical problems increase as well. However, the behaviour of AI is not only influenced by the mathematical models that make up the algorithm but also directly influenced by the data the algorithm processes. As mentioned, poorly prepared or biased data results in incorrect outcomes: ‘garbage in is garbage out’. While incorporating ethical behaviour in mathematical models is a daunting task, reducing bias in data can be achieved more easily using data governance.
The Theoretical Concept of Coherent Extrapolated Volition
High-quality, unbiased data, combined with the right processes to ensure ethical behaviour within a digital environment, could significantly contribute to AI that can behave ethically. Of course, from a technical standpoint, ethics is more than just usage of high-quality, unbiased data and having the right governance processes in place. It includes instilling AI with the right ethical values that are flexible enough to change over time.
To achieve this, we need to consider the morals and values that have not yet developed and remove those that might be wrong. To understand how difficult this is, let’s see how Nick Bostrom – Professor in the Faculty of Philosophy at Oxford University and founding Director of the Future of Humanity Institute – and Eliezer Yudkowsky – an artificial intelligence theorist concerned with self-improving AIs – describe achieving ethical AI [7]:
The theoretical concept of coherent extrapolated volition (CEV) is our best option to instil the values of mankind in AI. CEV is how we would build AI if ‘we knew more, thought faster, were more the people we wished we were, had grown up farther together; where the extrapolation converges rather than diverges, where our wishes cohere rather than interfere; extrapolated as we wish that extrapolated, interpreted as we wish that interpreted’.
As may be evident by CEV, achieving ethical AI is a highly challenging task that requires special attention if we wish to build Responsible AI. Those stakeholders involved in developing advanced AI should play a key role in achieving AI ethics.
Final Words
AI is going to become a very important aspect of the organisation of tomorrow. Although it is unsure what AI will bring us in the future, it is safe to say that there will be many more missteps before we manage to build Responsible AI. Such is the nature of humans.
Machine learning has huge risks, and although extensive testing and governance processes are required, not all organisations will do so for various reasons. Those organisations that can implement the right stakeholder management to determine whether AI is on track or not and pull or tighten the parameters around AI if it is not will stand the best chance to benefit from AI. However, as a society, we should ensure that all organisations – and governments – will adhere to using unbiased data, to minimising the influence of biased developers, to having a mixed data approach to include the context, to developing AI that can explain itself and to instil ethics into AI.
In the end, AI can bring a lot of advantages to organisations, but it requires the right regulation and control methods to prevent bad actors from creating bad AI and to prevent well-intentioned AI from going rogue. A daunting task, but one we cannot ignore.
This is an edited excerpt from my latest book. If you want to read more about how you can ensure ethical AI in your organisation, you can read the book The Organisation of Tomorrow.
References
[1] Yudkowsky, E., Artificial intelligence as a positive and negative factor in global risk. Global catastrophic risks, 2008. 1: p. 303.
[2] Van Lent, M., W. Fisher, and M. Mancuso. An explainable artificial intelligence system for small-unit tactical behavior. in The 19th National Conference on Artificial Intelligence. 2004. San Jose: AAAI.
[3] Bostrom, N. and E. Yudkowsky, The ethics of artificial intelligence. The Cambridge Handbook of Artificial Intelligence, 2014: p. 316-334.
[4] Hurtado, M., The Ethics of Super Intelligence. International Journal of Swarm Intelligence and Evolutionary Computation, 2016. 2016.
[5] Anderson, M. and S.L. Anderson, Machine ethics. 2011: Cambridge University Press.
[6] Bostrom, N. and E. Yudkowsky, The ethics of artificial intelligence. The Cambridge Handbook of Artificial Intelligence, 2014: p. 316-334.
[7] Bostrom, N., Superintelligence: Paths, dangers, strategies. 2014: OUP Oxford.
Image: S-Visual/Shutterstock

Dr Mark van Rijmenam
Dr. Mark van Rijmenam, widely known as The Digital Speaker, isn’t just a #1-ranked global futurist; he’s an Architect of Tomorrow who fuses visionary ideas with real-world ROI. As a global keynote speaker, Global Speaking Fellow, recognized Global Guru Futurist, and 5-time author, he ignites Fortune 500 leaders and governments worldwide to harness emerging tech for tangible growth.
Recognized by Salesforce as one of 16 must-know AI influencers , Dr. Mark brings a balanced, optimistic-dystopian edge to his insights—pushing boundaries without losing sight of ethical innovation. From pioneering the use of a digital twin to spearheading his next-gen media platform Futurwise, he doesn’t just talk about AI and the future—he lives it, inspiring audiences to take bold action. You can reach his digital twin via WhatsApp at: +1 (830) 463-6967.


